Launching the RFI-File-Monitor
Windows
When installing the Monitor using the Anaconda package manager, you should see an entry for it in the Start menu. Click it to launch the program.
Linux and macOS
Assuming you installed the Monitor using Anaconda, you will now need to activate the conda environment:
conda activate rfi-file-monitor
rfi-file-monitor
Do not attempt to bypass activating the environment by using the absolute path to the rfi-file-monitor executable: this will result in GLib related run-time errors!
Understanding the RFI-File-Monitor
Before going into a step-by-step guide on how to use this software package, it is probably best to share some of the concepts and terms it is built around to avoid any misunderstandings later on.
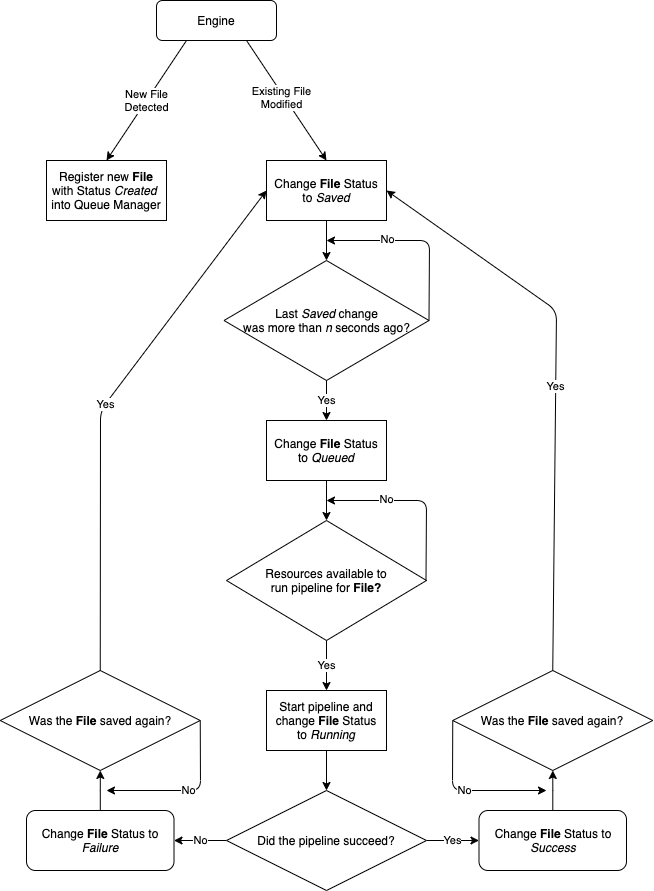
The engine is the main driver of activity: it monitors a provider for two kinds of changes:
- Newly created files
- Modified files
The provider can be a directory on the local filesystem, an S3 bucket, a file, …, depending on which type of engine was selected for the session.
Whenever a new file has been detected by the engine, a corresponding File object will be instantiated with status set to Created. This object is then added to the queue manager that is associated with the session.
Files with Created status are effectively ignored by the queue manager until the engine detects that they have been saved or modified: at this point will the queue manager be instructed to change File status to Saved, which is when things become interesting! After a configurable of time, and assuming no further modifications were detected for this file, will the File be queued for processing, corresponding to a change of status to Queued.
At this point will the queue manager check if the necessary resources to start the processing pipeline for the File are available: one thread is used per pipeline, with the total number of usable threads configurable in the queue manager settings. If the outcome of the check is positive, the pipeline will be started and the File status will be set to Running.
Processing pipelines consist of a list of operations, that is defined by the user. Each operation works directly on the File itself, not on any new files that may have been produced by a preceding operation! It is possible though, to pass information (metadata) down a File’s pipeline to influence the behavior of subsequent operations. In fact, one can make an operation explicitly depend on another one, producing a run-time error when this condition is not met.
The File status will be set to Success or Failure at the end of the pipeline, depending on its outcome. It should be noted that these statuses do not necessarily represent the final state for the File object. Indeed, it is quite possible that the engine detects more modifications of the observed file, leading to its status being reset to Saved, which will eventually lead to the File being requeued for processing…
This section can be visualized using the following flowchart:
File types
The File objects that were first used in the previous section are in fact instances of a base class with the same name. Several implementations of this base class exist in this software package, and it should not be hard to write your own. Important here is that the objects that are created by a particular engine, are always instances of the same class, derived from File, the exported filetype. Operations however, can be written to support as many filetypes as necessary.
The following table summarizes the currently available file types, as well as the engines and operations that support them:
| Filetype | Supporting Engines | Supporting Operations |
|---|---|---|
| RegularFile | Files Monitor, Temporary File Generator | Dropbox Uploader, Dummy operation, Local copier, S3 Uploader, SciCataloguer, SFTP Uploader |
| Directory | Directories Monitor | Directory Compressor, Dropbox Uploader, Dummy operation, Local copier, S3 Uploader, SciCataloguer, SFTP Uploader |
| URL | URLs from File Loader | Dummy operation, URL Downloader |
| S3Object | AWS S3 Bucket Monitor, Ceph S3 Bucket Monitor | Dummy operation, S3 Copier, S3 Downloader |